
数据结构:是指在计算机中存储和组织数据的方式。它们帮助我们更有效地管理和操作数据。常见的数据结构包括数组、链表、栈、队列、树和图等。
算法:解决问题的一系列步骤或方法。在计算机科学中,算法通常表现为一系列指令,用于解决特定的运算和逻辑问题。
算法五大特性:输入、输出、有穷性(有限的步骤自动结束,可接受的时间内完成)、确定性(算法每一步都有确定的含义,不会出现二义性)、可行性(每一步计算机可行,每一步都能够执行有限的次数完成)。
时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)。最优时间复杂度(最少基本操作)、最坏时间复杂度(最多基本操作)【一般关注这个】、平均时间复杂度。
“大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。
常见的时间复杂度:
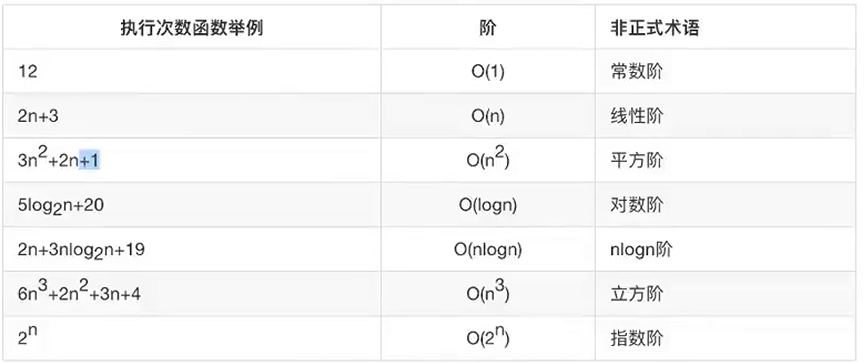
O(1)<O(logn)<O(n)<O(nlogn)<O(n^3)<O(2^n)<O(n!)<O(n^n)
Python内置函数时间效率
timer1 = timeit.Timer('test1()','from __main__ import test1')
print(timer1.timeit(10))顺序表
一体式结构+分离式结构
python中list和tuple就是顺序表实现。
list是一种元素个数可变的线性表,元素外置【顺序表表存储的是地址】,可以加入和删除元素,并在各种操作中维持已有元素的顺序【保序-即更改元素顺序保持不变,如123,插入,1423,而不是1432,复杂度O(n)】。采用分离式技术实现的动态顺序表。
特征:基于下标位置的高效元素访问和更新,时间复杂度应该是O(1);允许任意加入元素,而且在不断加入元素的过程中,表对象的表示不变。
在Python的官方实现中,list就是一种采用分离式技术实现的动态顺序表。这就是为什么用list.append(x) (或 list.insert(len(list), x),即尾部插入)比在指定位置插入元素效率高的原因。
在Python的官方实现中,list实现采用了如下的策略:在建立空表(或者很小的表)时,系统分配一块能容纳8个元素的存储区;在执行插入操作(insert或append)时,如果元素存储区满就换一块4倍大的存储区。但如果此时的表已经很大(目前的阀值为50000),则改变策略,采用加一倍的方法。引入这种改变策略的方式,是为了避免出现过多空闲的存储位置。
题目与回答
一、基础概念题
数据结构与算法的关系:
请用一个具体的例子(比如“在图书馆中查找一本书”)来阐述数据结构(书架的排列方式)和算法(你查找书的方法)是如何相互关联,共同影响效率的。
回答:以图书馆找书为例,数据结构就像是图书馆书架排列方式,可以按照书名进行A-Z排列,也可以按照书籍内容划分不同的分类,进行分类排列,再按照A-Z排列。算法就像是查找策略,如果A-Z排列,我们就按照书名去找对应的字母书架。如果书籍内容分类排列,我们就要先去找书籍内容所属分类,再A-Z查找。如果第二种直接A-Z查找,那么会导致查找效率非常低。
算法五大特性辨析:
请判断以下描述是否符合算法的五大特性,并简要说明理由:
a) 一个算法在执行过程中,如果遇到除以零的情况,程序会崩溃。
b) 一个寻找质数的算法,如果质数是无限的,它会一直运行下去。
c) 一个算法为了提高效率,在某些步骤中,允许根据随机数来决定下一步的操作。
回答:a不符合,因为不具备可行性。b不符合,不具备有穷性。c不符合,不具备确定性。
时间复杂度排序与实例:
请从你列出的常见时间复杂度中,选择 O(n)、O(n log n)、O(n^2) 这三种,并分别举一个 Python 代码片段的例子来对应它们的时间复杂度。
# O(n)
n=10
for i in range(n):
print('hello')
# O(n log n)
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = arr[:mid]
right_half = arr[mid:]
left_sorted = merge_sort(left_half)
right_sorted = merge_sort(right_half)
return merge(left_sorted, right_sorted)
def merge(left, right):
merged = []
left_idx, right_idx = 0, 0 # 左右的指针
while left_idx < len(left) and right_idx < len(right):
if left[left_idx] < right[right_idx]:
merged.append(left[left_idx])
left_idx += 1
else:
merged.append(right[right_idx])
right_idx += 1
merged.extend(left[left_idx:])
merged.extend(right[right_idx:])
return merged
# 假设有个初始数组
a = [1,3,5,2,6,4]
# n = 1000 # 假设n是输入规模
# import random
# large_list = [random.randint(0, n*10) for _ in range(n)]
sorted_list = merge_sort(a)
print(sorted_list)
# O(n^2)
count = 0
for i in range(n): # 外层循环执行 n 次
for j in range(n): # 内层循环执行 n 次
count += 1 # O(1) 操作,总共执行 n * n 次
二、Python实现与分析题
Python list 的“分离式结构”:
a) 请解释为什么 Python 的 list 采用“分离式结构”能够使其存储不同数据类型(如 int, str, list, dict 等)的元素?
回答:list存储的不是数据本身,而是一个引用或者说是内存地址。甭管什么数据类型,他的内存地址是同样大小的,其内部维护的是一个连续的、固定大小的内存区域,这个区域的每个“槽位”都用来存放一个统一大小的对象引用。而实际的数据对象存储在内存的堆区,他们的大小可变。
b) 这种“分离式结构”相比于C语言中固定大小数组的“一体式结构”,其主要缺点是什么?(从内存访问和缓存的角度考虑)
回答:分离式结构相对于一体式结构,一个问题是存储空间利用效率没那么高,需要额外的存储空间来存储地址或者指针,如果面对大量小对象(比如整数)的数据时,其存储空间消耗相对于一体式结构就更加突出。访问速度相对慢一下,因为需要先找到内存地址或引用,再找到具体的对象,需要两次访问内存,而且因为分离式结构数据存储在不同的位置,每次访问,都需要加载一个新的缓存行,这会显著减低访问性能。
list.append() 与 list.insert(0, x) 效率分析:
a) 解释 list.append(x) 的均摊时间复杂度为什么是 O(1)。在什么情况下,它的时间复杂度会退化到 O(n)?
回答:append是在顺序表末尾追加一个对象,而顺序表本身是按照一定顺序的,那么只需要或许第一个指针地址+数据长度即可得到新的对象指针,插入即可。前面的那些已有的指针不要调整。不清楚什么情况下会退化到O(n)。但是当 list 的当前容量已满,且需要添加新元素时,它就必须进行扩容。扩容就是分配一块更大的新的连续内存空间,将所有旧内存空间中的元素引用复制到新的内存空间中。释放旧的内存空间。这个复制所有 n 个元素引用的操作,其时间复杂度是 O(n)。
b) 解释 list.insert(0, x) 的时间复杂度为什么是 O(n)。
回答:因为要保证顺序表中元素的顺序,也就是说,在顺序表初始位置加入一个数据,后续每个数据的引用都需要向后调整。